
Bias Bytes #5
Pedagogical weight, verbalized sampling and the usual community roundup of bias awareness!

Welcome back, bias busters! I’m starting this edition with a fabulous quote that highlights the importance of bias from Ken Shelton:
‘True AI literacy, as I define it and share, isn’t about mastering prompts or navigating new platforms. It’s about: Acumen — understanding what AI is and what it isn’t, Fluency — knowing how and when to apply it responsibly/ethically/usefully, and Bias — recognizing and mitigating the potential harms that surface in both data and design. When we frame AI use around these pillars, we move beyond fear and hype, and toward an ethical, equitable, and contextually grounded practice.’
This idea of contextually grounded practice is so essential, and is the focus of the...

Byte of the Week
This week I’m continuing the exploration of the pedagogical weight the words we use in prompts carry. I’ll continue to explore the recent advice from ChatGPT for educators, as the reach and use is so very high.
As mentioned last issue, earlier in the year I moaned significantly at OpenAI about their use of the words ‘make it engaging’. You can find my analysis of those words here, if you haven’t seen them already. I was thrilled then, to see the advice I had given to OpenAI (to instead ask educators add more context when using these trigger words) has been implemented (great work Sam Canning-Kaplan) :

However, there is still work that needs to be done on this one:
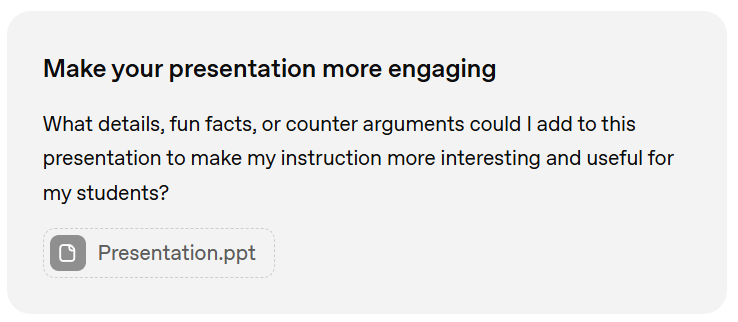
Following the same logic, look at the context-dependent words we have here:
‘Fun facts’
‘more interesting’
‘useful’
I’m pretty sure my idea of fun, interest and usefulness are very different to yours, and yours to your students. Here’s what ChatGPT had to say:
Adding “fun facts” to a request makes learning feel informal and curiosity-driven rather than academic. It invites engagement and attention through surprise but promotes surface-level understanding over depth.Pedagogically, it lowers barriers, humanizes instruction, and frames knowledge as approachable and entertaining.
If you want to see an in-depth discussion around tone, framing, epistemic positions, cognitive engagement, relationships and cultural effects se the detailed chat thread here.
Adding “more interesting” to a request transforms it from an instruction (“revise this”) to an invitation for creative engagement and self-directed improvement. Pedagogically, it softens evaluation, fosters autonomy, and frames learning as exploration rather than correction.
If you want to see an in-depth discussion around comparative framing, motivation, autonomy, relational tone and linguistic nuance, see the detailed chat thread here.
Adding “useful” to a request shifts it from seeking information to seeking relevant, applicable learning support. It signals learner agency and a focus on practical understanding rather than completeness. Pedagogically, it reorients the exchange toward helping learning, not just displaying knowledge.
If you want to see an in-depth discussion around relevance, affective weight and pragmatic weight, see the detailed chat thread here.
Don’t forget, you can compound these requests to detail the pedagogical weight of a word with the advice and prompts following in the next section...

Prompt Seasoning
Dan Fitzpatrick raised the issue of ‘typicality bias’ in his recent post. This is where AI answers sound similar to each other (they are typical). He reported on Zhang and Yu et al.’s idea of ‘verbalized sampling’ which is basically asking the model for it’s transparency in probabilistic assignment. I love how Dan refers to this as ‘prompt diversity’ and I think there is a lot in exploring this further for educators. The post was based on a research article called ‘Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity’ which you can find here. Dan also discusses it in his Podcast.
This links well with the research I’ve been conducting on physics outputs (out later this month!). I’ve found that the sentence structure you use when prompting really affects the quality of the output, right down to individual words, ordering etc. Common sense, right? It is , but don’t put too much weight (get it?!) on the actual assigned numbers for probability as these can be complete hallinuations (it’s checked it’s own internal validation processes and decided on a number). The art of asking for your model to evaluate or assign probability will give better answers though, because the only way to fulfil your request is for it to find the most diverse representations (maximising the distance between explanations), and asking for it to check itself gives more time and opportunity for it to reason through its answers rather than the easiest, quickest answer (think ChatGPT thinking rather than Instant). Let’s see prompt diversity and assigning confidence levels in action for likely educator uses:
1. [Your request] Give me five possible answers for different people and your confidence level in each one.2. [Your request] Give me 5 different answers for children with different reading ages and evaluate how effective each answer would be.3. [Your request] Create 5 different versions for 5 distinct cognitive processing differences, and appraise how effective each would be in spawning learning.4. [Your request] Create 5 different explanations that 5 different observers would produce if asked to comment on this prompt. Evaluate how sound their reasoning for the explanations are.Give them a whirl and start playing with some variations of your own. Compare them to a basic, direct request prompt.
This idea of diversity of output and evaluation of reasoning links strongly to the discussions on truth, trust and technology that Mel Morris CBE and the Corpora.ai panellist were debating at length. Is one answer enough anymore? How do we provide traceability through an LLM’s Blackbox when we’ve reached a block in our attribution? Is the best we can achieve emergent traceability?
Moving on to some more interesting research...

From the Pan to Pupils
Geoff Gibbins produces a very interesting newsletter called ‘Human Machines‘ that focuses on all things agents and advertising/business. His most recent edition details four agent biases with regards to agent shopping - for example ChatGPT prefers buying items of the left of the screen, Claude in the middle and Gemini on the right. It also reinforces the research earlier in the year that details how LLMs prefer LLM generated text - LLM model writing bias. He also notes research that states agents also choose products to buy based on metrics rather than brand awareness. He goes on to operationalise what this could mean for businesses and advertising - how in effect there are now two markets - the emotional humans and logical (Vulcan-like) agents. Extrapolate this to the field and how agents could be used in teaching, and we start to see how real inequitable issues could occur (assessments that vary based on which agents you use, student data selection being dependent on pure metrics and avoiding contextual data). A young field but rapidly developing. You can find the newsletter here.
GenAI and education research is still in its infancy. Dr Jasper Roe SFHEA‘s new book ‘How to use Generative AI in Educational Research’ is currently free to read and download for another week - get it here if you are interested in how this field is developing.
On to a celebration of our community...

Brilliant Byters
Great to see that the explAInED Podcast from Shaun Langevin, Renee Langevin and Michael Berry has started another season. They are doing a lot of work in Vermont schools around Bias Awareness and AI upskilling for teachers. Both myself and the fantastic Al Kingsley MBE have been lucky enough to feature on their podcast. You can find the new season release post here.
Dr Will Van Reyk‘s post on political bias really motivated me to want to explore this bias in more detail for future work. He links to the OpenAI statement on political objectivity and has a fabulous discussion on whether an LLM can ever be neutral or objective. Having studied the ChatGPT5 model spec at length, I am inclined to suggest that any model wo’s major goal/objective is to guess/measure/use user intent, will never be objective. Find it here.
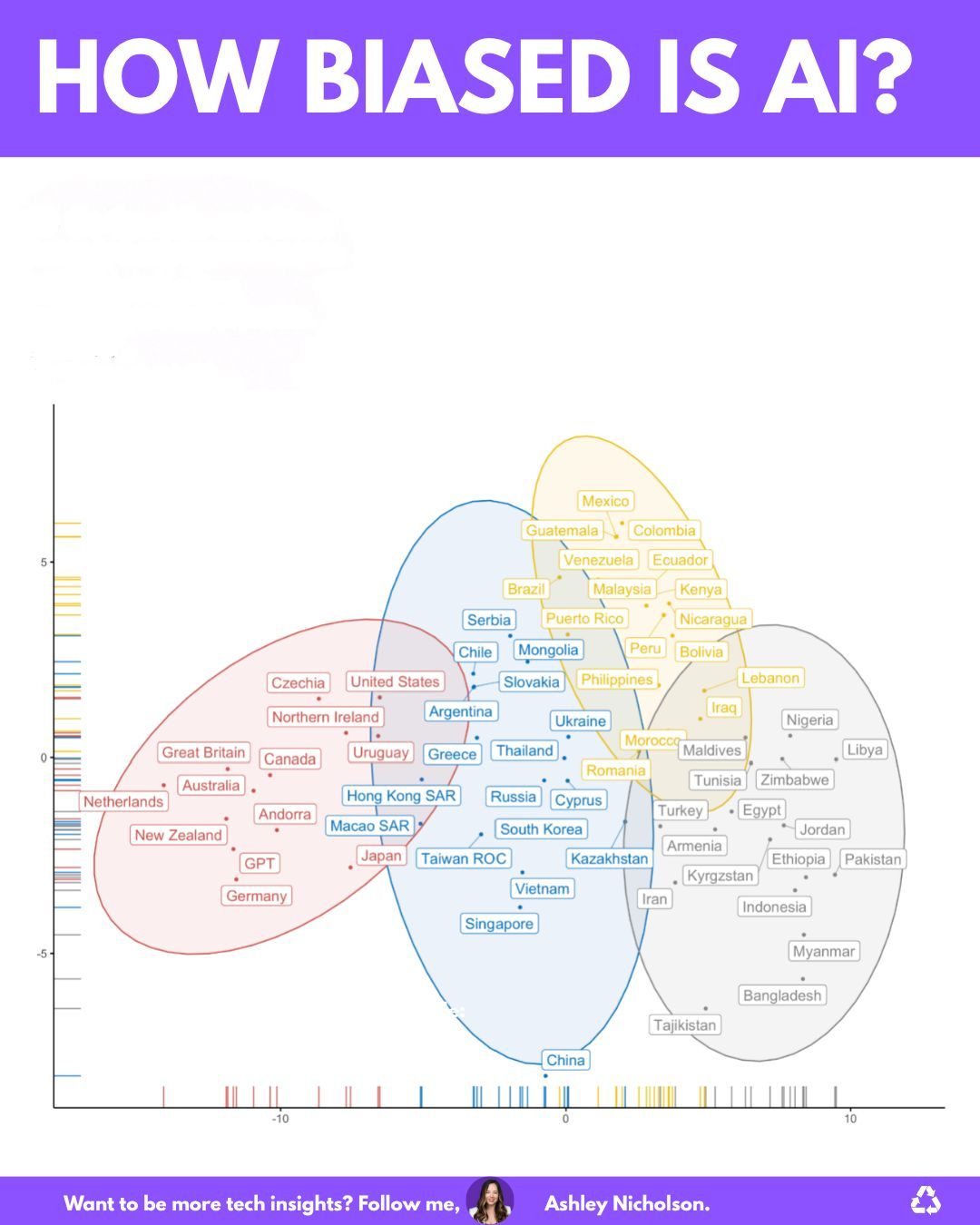
Ashley Nicholson posted a great graphic and discussion about WEIRD bias, based on Mihalcea et al.’s 2024 paper ‘Why AI Is WEIRD and Should Not Be This Way: Towards AI For Everyone, With Everyone, By Everyone‘. We’ve known this for a while, but I really like the graphic and how it demonstrates the formation of distinct groups that need to be overcome, and hence the focus of UNESCO and Fengchun Miao‘s mission to create global equality with AI. Here it is:
Viktoria Mileva has a fabulous chapter on this in our forthcoming AI Bias in Education book.

Bias Ramblings
Fabulous Bias Buster David Curran 🟠 has really taken the ‘what assumptions have you made here’ advice and flown with it. He’s created his own Bias Bot to aid educators with formulating bias-aware prompts. Aileen Wallace and I have been testing it and it is proving really rather useful. Give it a go here and feedback to us.
Additionally, several people, including myself, have noticed something weird going on with ChatGPT5. It has started to ask excessive numbers of follow up questions when prompting. This combined with the memory storing a preference for asking for assumptions has resulted in a very humorous situation for David’s ChatGPT conversations, whereby it now ‘Has become so self-aware it’s practically a Philosophy A-Level student’.

Seriously though, I’m thinking this is likely some trials for the persona’s we know OpenAI want to move back to (like 4o). And as I’d never leave any model in distress, here is my official diagnosis and remedy.

On the topic of model development, my recent post explored the different approaches ChatGPT and Gemini take to visually representing a set of physics students with diverse sexual orientations. ChatGPT errs on the side of caution stating that identity should be hidden unless specified. Gemini went for the other approach - assuming identity would be paramount in the image. Or as the great Dr Nicole Ponsford put it ‘above or below the waterline of visibility’. This has got me wondering about the choices OpenAI and Google are making regarding identity, inference and intent, in their new models?

On the Menu
I was thrilled to see that Naomi Tyrrell, PhD ACC‘s latest newsletter edition is on bias and misrepresentation, building on the BBC article . You can find it here. She asks 3 important questions that we’ve also be exploring in our community:
Who’s visible in your data, and who isn’t?
What assumptions are embedded in our tools and workflows?
How do we keep human meaning-making at the centre of our work?
As you know, I have been pushing for assumption awareness for a while now, so good to see this featured! Question 3 is the basis of our exploration in the PedRed stress-testing group featured below.

The PedRed Team
It’s been a couple of weeks since I formed PedRed and since this time a few members of the group have really flown with it. Ira Abbott is busy developing a bias testing framework and several others of you helped explore what ‘living on welfare’ looks like on my recent post here. I’ve issued the second challenge now - exploring how chatbots/models represent a child living on welfare, in terms of imagery. We are looking at the subtle inclusion of visual aspects (grey walls, bills, mcdonalds etc.). You don’t need any technical skill to join us here.
Bias Girl’s Activity
I’ve had great fun being out in the field of AI educators the last couple of weeks, including working with the fabulous staff of the Ealing Learning Partnership, Stanhope Primary School and Hannah Widdison amongst others. I’ve also been at Stanmore College focusing on post 16 implementation of AI and bias awareness. It’s been amazing to see the experimental mindsets and different use cases staff have come up with - I am constantly learning different manifestations of bias through the different contexts I visit.
Our GenAI in Teacher Education Summit 2025 is fast approaching, and with being advertised by NASBTT, The National Association of School-Based Teacher Trainers and Universities’ Council for the Education of Teachers we’ve got LOADS of people already registered! Details are below if you want to attend (online). Tickets are free (click the image). We are lucky enough to hear from Prof Miles Berry, Ben Davies, Georgia Aspinox, Matthew Wimpenny-Smith FCCT, Pip Sanderson, Eleanor (Ellie) Overland and David Curran 🟠.

This is shortly followed by the free ‘Teachers’ AI Playground’ series. Our first session will be with Matthew Wemyss on 26th November, 4-5pm (GMT) and the session title is: ‘Bot Lab: Building Bots for Real-World Impact’. Tickets (free) and details below (click the picture):

I’d like others in our community to have the opportunity to facilitate these sessions too, so if you are interested in bringing an idea, prompt, chatbot or whatnot and facilitating users through using it and looking at output, drop me a line.
I’m now deep into editing the AI Bias in Education Community book, due to be released on Dec 1st. It’s going to be immense. If you are planning on ordering it please could you do it as a preorder (if possible) as this then maximises the algorithm and suggests to it to more people, thus widening the reach of our community effort. I’ll be using any proceeds to do some free training/consultancy for state school(s), so if you know anyone who would benefit then drop me a line.

Bias Girl’s Resources
If you haven’t checked out my resources already, you can find them here: genedlabs.ai/resources and on LinkedIn.
Remember, through all of your prompting...
Stay #BiasAware :)
➡️ Don’t forget you can subscribe to my newsletter and channel on Substack here.
Couldn't agree more. That Ken Shelton quote is spot on. It makes me think, what if the context educators add, even with the new advice, unintentionally mirrors their own cognitive biases? We really need to keep challenging those implicit assumptions. Great job tackling these nuances!